Meet DOLCE, a generative AI tool that can reconstruct CT images from limited-view data
Ulugbek Kamilov and Jiaming Liu developed a sophisticated deep learning model that can create high-quality CT images from severely limited data and quantify the uncertainty in the reconstructed images
When it comes to imaging, more is more. More data enables sharper, more accurate images, but gathering complete data isn’t always practical or even possible. For situations where data is limited, Ulugbek Kamilov and Jiaming Liu in the McKelvey School of Engineering at Washington University in St. Louis collaborated with researchers at the Lawrence Livermore National Laboratory to develop a new tool to do more with less.
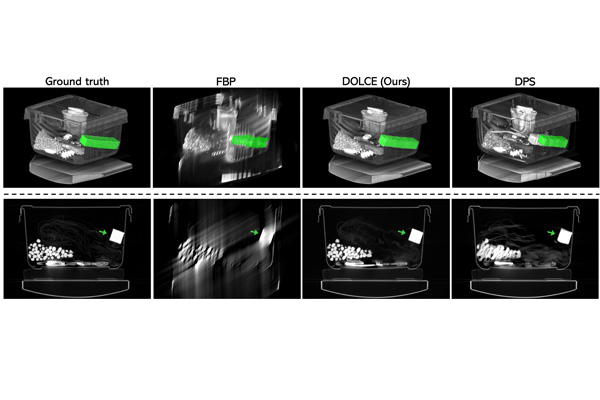
In a paper presented Oct. 5 at the International Conference on Computer Vision (ICCV) in Paris, France, the team introduced DOLCE, a deep model-based framework designed to overcome the challenges posed by limited-angle computed tomography (LACT). LACT is an imaging technique used in applications ranging from medical diagnostics to security screenings. However, the limited angle coverage in LACT is often a source of severe artifacts, or discrepancies between the reconstructed image and ground truth.
“At the heart of this project is an interest in recovering missing data,” said Kamilov, associate professor of electrical & systems engineering and computer science & engineering. “To complete a CT taken at a limited angle or a short MRI taken over a limited time, we can use the data or the parts of the image we do have to extrapolate what’s missing.”
DOLCE, which stands for diffusion probabilistic limited-angle CT reconstruction, uses a cutting-edge generative AI model to create multiple high-quality images from severely limited data. While generative AI models can create realistic data, their output might not be accurate. One of DOLCE’s major advantages is that it harnesses the power of AI while also providing tools to quantify its reconstruction uncertainty.
“DOLCE lets us generate realistic images, but it also ensures consistency with the measured data, and shows variance and uncertainty,” Kamilov said. “Unlike traditional generative models, such as the large language models people are now familiar with through chatbots, DOLCE is always consistent with what’s actually there, with the measured data and with the physical properties of the underlying system. DOLCE also gives a variance map to show all possible variants it could have produced based on the data provided.”
In their paper, Kamilov and first author Jiaming Liu, a doctoral student in electrical & systems engineering, show the range of DOLCE’s capabilities as a realistic image generator in two key applications: airport security in scanning checked luggage and medical imaging of the human body. By experimenting with real LACT datasets, Liu showed that DOLCE performs consistently highly on drastically different types of images. This versatility makes it a promising tool for improving the quality of reconstructed LACT images.
While Kamilov and Liu noted the DOLCE is not designed for medical diagnostics, it does provide a realistic view of what might be ground truth as well as the variations possible in the images it generates. This is especially useful for applications where it’s impossible to collect all the angles due to physical or time limitations.
“As engineers, our job is to show our colleagues in medical and other domains what this technology is capable of and then work with our collaborators to pick or develop suitable tools for specific applications,” Kamilov said. “With DOLCE, we’ve innovated a state-of-the-art computational imaging technology using the latest generative modeling capability.”
Liu J, Anirudh R, Thiagarajan JJ, He S, Mohan KA, Kamilov U, Kim H. DOLCE: A model-based probabilistic diffusion framework for limited-angle CT reconstruction. International Conference on Computer Vision (ICCV), Oct. 2-6,2023. https://wustl-cig.github.io/dolcewww/
This work was performed under the auspices of the U.S. Department of Energy by Lawrence Livermore National Laboratory under Contract DE-AC52-07NA27344. This work was funded by the Laboratory Directed Research and Development (LDRD) program at Lawrence Livermore National Laboratory (22-ERD-032). LLNL-CONF-816780. This material is based upon work supported by the U.S. Department of Homeland Security, Science and Technology Directorate, Office of University Programs, under Grant Award 2013-ST-061-ED0001.